Agentic QA.
A regression-testing harness for AI-driven applications. Tests are written as agent skills, not imperative scripts. Evidence is verified on disk. The LLM never marks its own work.
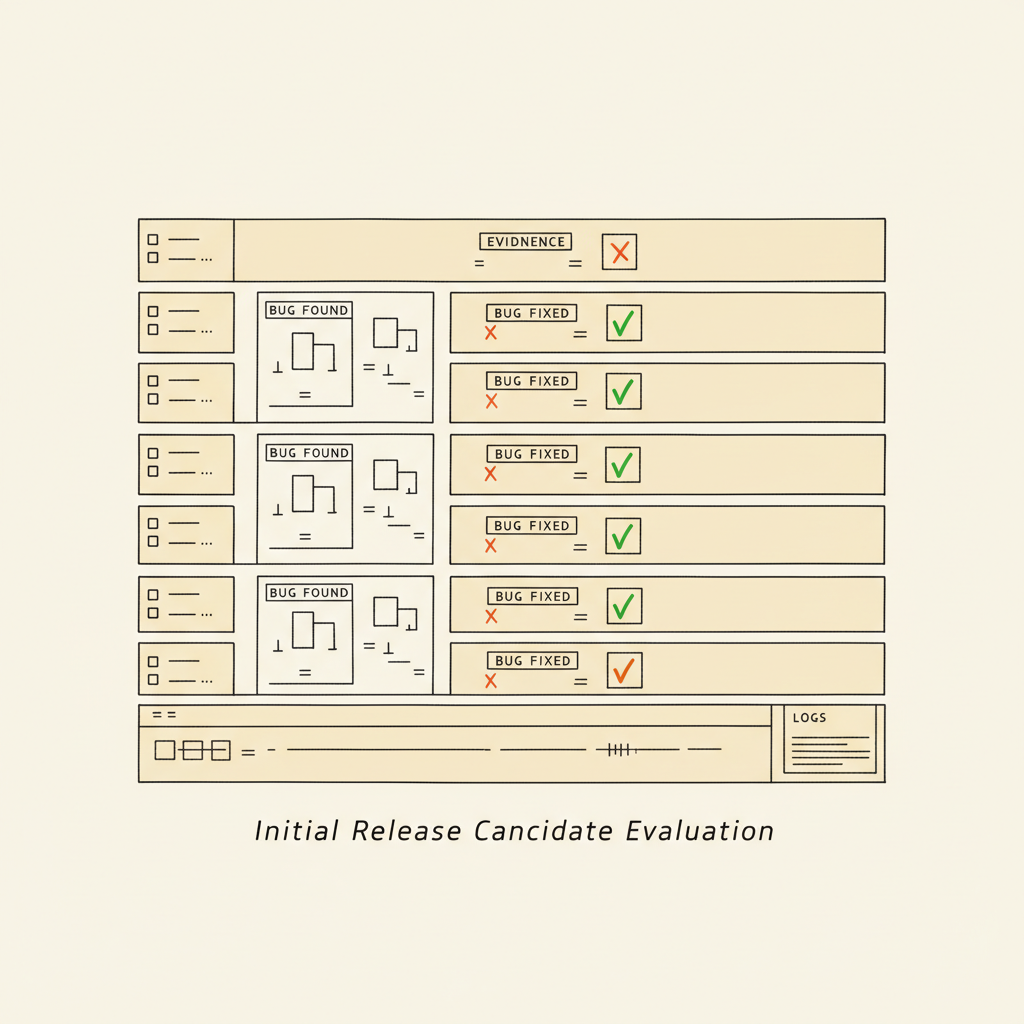

The test passed. The AI was wrong.
Selenium-era tools were built for a world where the system under test was deterministic. Same input, same output. The first generation of LLM-powered apps broke that assumption — and most testing tools haven't acknowledged the break.
The pattern shows up like this. A team adopts an LLM-driven test recorder. Tests get generated faster than humans can write them. The dashboard goes green. Six weeks later a customer reports a bug that has been live for a month — through every green build along the way.
What happened? The recorder used an LLM to decide whether each test step succeeded. The LLM, asked "did this work?", answered "yes." The test was marked passed. The failure was real, the verdict was wrong, and nobody had a way to know.
That gap — between "AI says it passed" and "the test actually passed" — is the entire problem Agentic QA exists to close. It's not a marginal improvement on existing test runners. It's a different shape of testing tool, built for a different shape of application under test.
Agent-based test skills + a visual command center.

Two ideas, working together.
Tests as agent skills. Each test is declared as a YAML skill — a named scenario with an ordered list of steps and a set of verification rules. Steps are atomic actions: navigate, click, fill, assert, screenshot. The skill is what the harness runs; the LLM is what the harness uses when a step needs to resolve something a selector alone can't (a shifted element, a form that needs realistic data, an ambiguous match). The script is never a tool the LLM picks up. The LLM is a tool the script picks up when it needs to.
This matters because it inverts the default. In the LLM-first test recorders, the model is the orchestrator and the test framework is the assistant. In Agentic QA, the test framework is the orchestrator and the model is the assistant. When the verdict is rendered, the model has no say in it.
The verdict is deterministic, always. A separate verifier module — which never calls an LLM, ever — walks the step results, checks URL matches, checks text matches, checks screenshot existence on disk, and emits PASS or FAIL. An integrity loop runs every thirty seconds and demotes any "passed" execution whose evidence has been deleted. Audited evidence. Auditable verdict. The cultural rule the harness keeps repeating: AI cannot mark its own work.
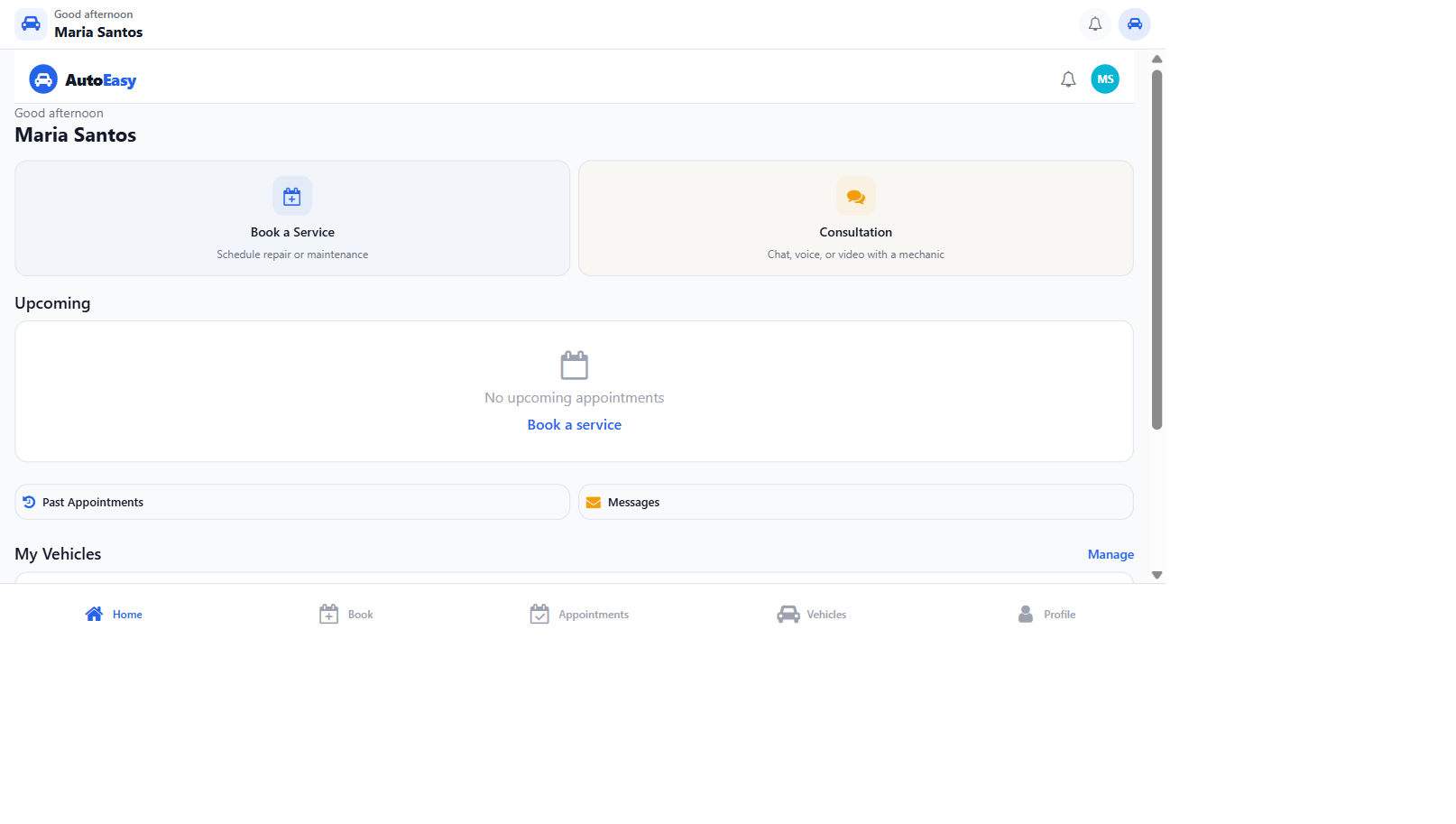
A visual command center for orchestration. The dashboard is the operator's surface — a single screen for running tests, watching them execute, and inspecting what came out the other side. Skill list. Executions log. Role tabs (Customer, Shop Owner, Mechanic for the first deployment; configurable for any application under test). Run buttons that pick which model drives the agent for that run. A per-step coverage panel that shows exactly which steps fired and which didn't. A bug-detail view for every failure. A live integrity score for the whole pipeline.
Promoting QA tooling from "report viewer" to "command center" is itself a position. When the product under test is non-deterministic, the human-in-the-loop needs to watch the system watch the system. The dashboard is where that happens.
Real bugs found. Real fixes verified.

The strongest evidence the design works is that it works. These are screenshots from real test runs of Agentic QA against its first customer application. In each pair, the harness flagged a bug that was live in the product, the developer fixed the underlying code, and the harness re-ran the same skill and verified the fix — same skill, same evidence pipeline, same deterministic verifier.
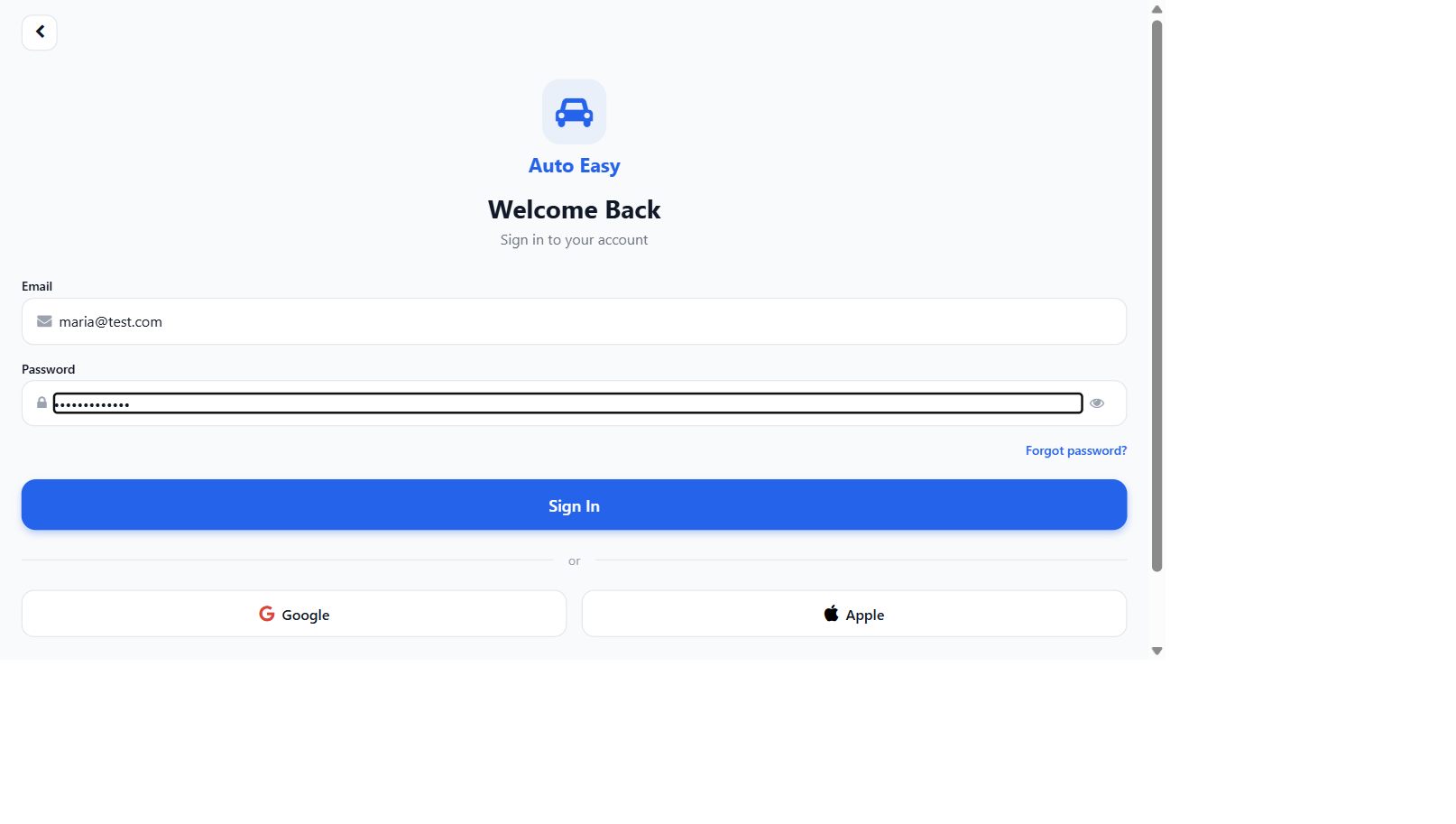
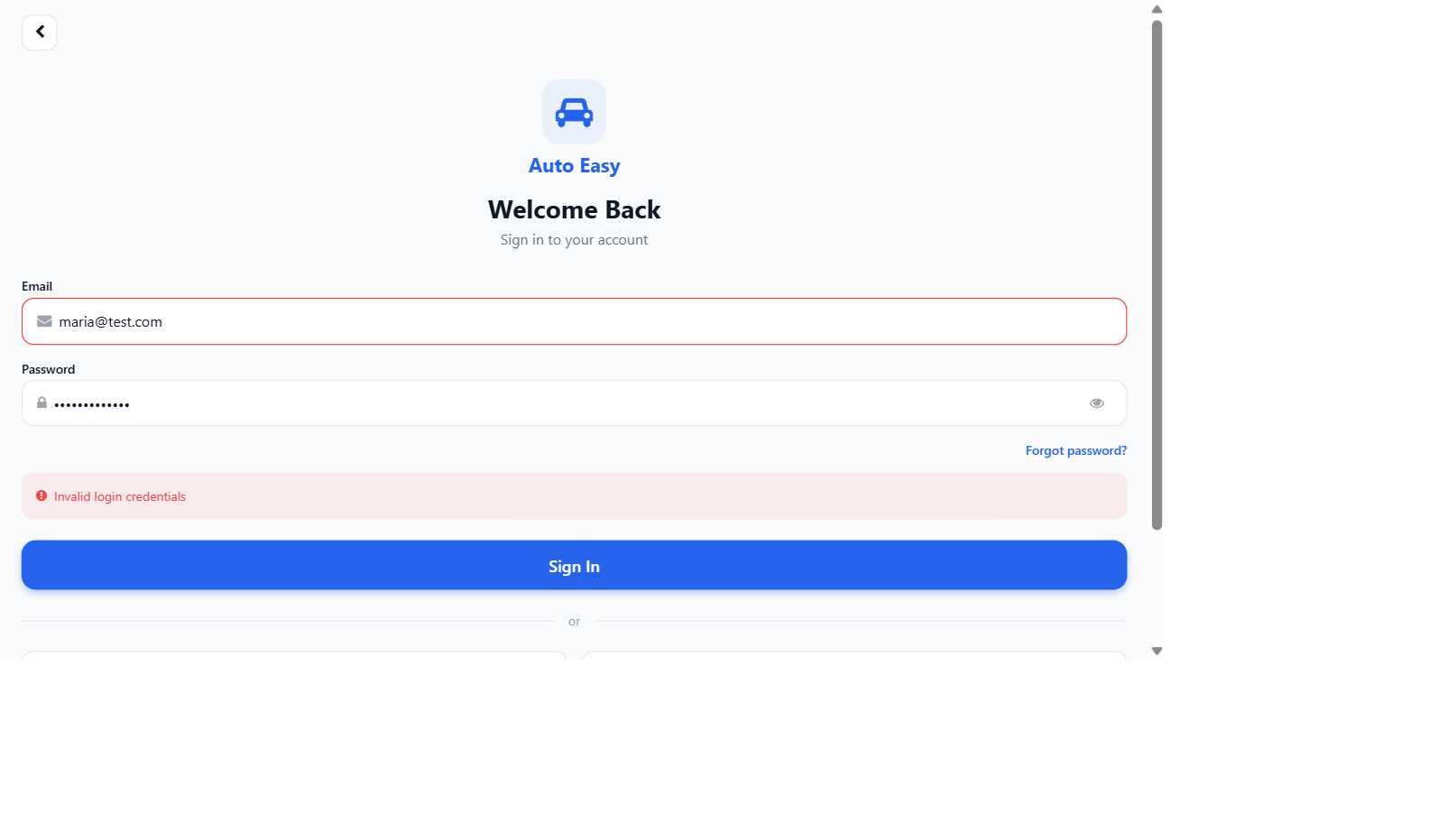
Both bugs are the kind that a green-on-paper test suite misses every time. They look fine if you ask an LLM. They fail if you check the actual rendered behaviour against an actual rule. That is the difference Agentic QA is built around.
One customer in production. Designed for many.
Today's deployment is against the studio's own auto-services booking app — Auto Easy. The harness has hundreds of YAML skill definitions, dozens of historical test executions on disk, and a live operations dashboard that tracks the app's regression coverage in real time. Auto Easy is a serious AI-driven application — half-a-dozen LLM-touched flows, a domain that doesn't tolerate hallucinated bookings, real customers waiting on the other end. If the harness can hold the line for Auto Easy, it can hold the line for most applications of similar shape.
Auto Easy is the first customer, not the only one. Every primitive in the harness — YAML skills, deterministic verifier, evidence pipeline, integrity loop, command-center dashboard — is application-agnostic. The role tabs are configurable. The endpoints are configurable. The skill library is something a customer adopts as a starting point and grows on top of. The harness was architected from the start as a product the studio could sell to other software teams that need real regression coverage on AI-driven applications, not as a one-off internal tool.
Self-hosted today. Multi-tenant SaaS planned.
The current shape is a self-hosted harness — install it next to the application under test, point it at the dev server, run skills locally or in CI. That shape works for teams who want their test evidence on their own infrastructure, which most teams building AI-driven products do.
The next shape is a multi-tenant SaaS — managed instances, per-customer browser pools, S3-backed evidence storage, an auto-generation service that scans a customer's codebase and documentation to produce roles, use cases, and skill definitions automatically. The architecture is already organised around the service facades a SaaS evolution needs; the work to come is the productisation around them.
- Today. Self-hosted harness. Single-tenant. Disk-backed evidence. Dashboard at localhost.
- Next. Managed self-hosted — we install and operate the harness inside a customer's environment for them.
- Later. Multi-tenant SaaS with auto-generation of skills from a customer's existing codebase and documentation.
Same harness underneath. Customers who want data residency stay self-hosted; customers who want zero ops adopt the SaaS when it ships.